联邦策略:FedSTC#
概览#
Sparse method |
Quant method |
Residual |
Encoding |
Upstream |
Downstream |
|
|---|---|---|---|---|---|---|
FedSTC |
topk |
binarization |
Yes |
Golomb |
Yes |
Yes |
Handle Non-IID |
Handle Dropping/Skipping |
Generality |
||||
Fine //TODO |
Caching and synchronizing |
General |
FedSTC的主要motivation是为client和server之间的通讯做压缩,主要的贡献如下
相比之前仅在upstream(client 2 server)上做稀疏化的工作,FedSTC在downstream(server 2 client)上也做了稀疏化
在每一轮只有部分client参与的情况下,在server侧提供了Weight Update Caching的机制,每个client在参加下一轮训练之前必须同步最新的模型,或者是和global weights相比落后的updates;(我理解这样的motivation是如果只更新部分updates,可以让要传输的内容是稀疏的)
在做稀疏化的同时加上了量化,量化的方法是Binarization,最终的矩阵中只会出现3个数字,${-\mu,0,\mu}$;
在稀疏+量化后的矩阵上使用了无损的Golomb Encoding
设计#
Sparsity(topk)#
仅有upstream sparse的情况: 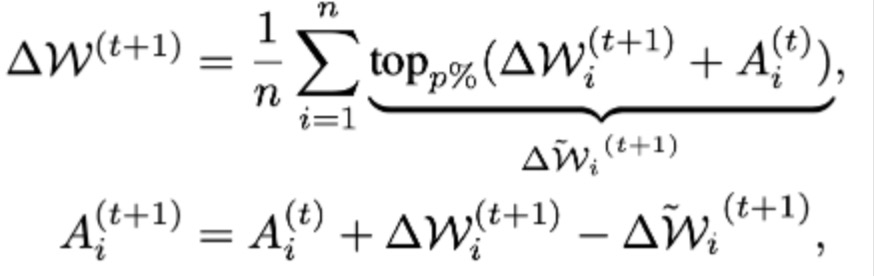 加上downstream:
加上downstream: 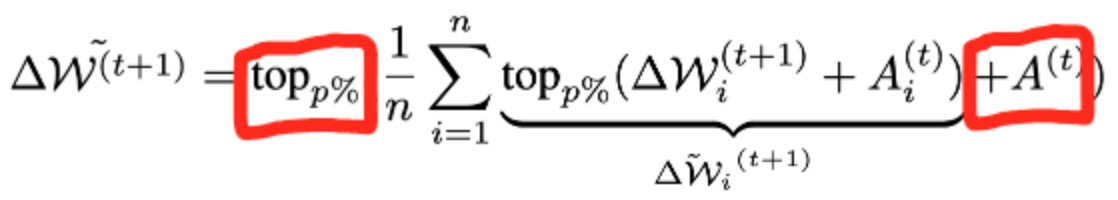 A是上一轮server侧的Residual,状态;
A是上一轮server侧的Residual,状态;
Caching#
The server keeps the most recent historical updates:
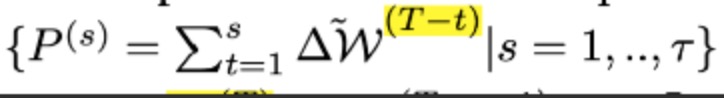
最新的 global weights 可以表示为:
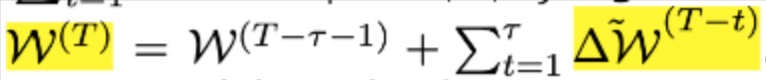
一个client再次加入训练的时候,必须更新相应的 $P^{(s)}$ 或 $W$;
Binarization (quant -> ternary tensor)#
$$ e’ \in {-\mu,0,\mu}, \mu = mean(abs(e)) $$
假设mu是sparse后的matrix中所有元素绝对值之和,matrix中非0的元素都被按照符号二值化为 $\mu$ 或 $-\mu$;
Pseudo Code on Compression#

Lossless Encoding#
Golomb Encoding
Experiment#
在不同的模型+数据集上做实验:
model |
dataset |
|---|---|
VGG11 |
CIFAR |
CNN |
KWS |
LSTM |
Fashion-MNIST |
Logistic R” |
MNIST |
FedAvg作为baseline之一,为了和FedSTC在传输成本上横向对比,FedAvg使用delay period,例如对sparse rate = 1/400的FedSTC,delay period为400 iterations; |
|
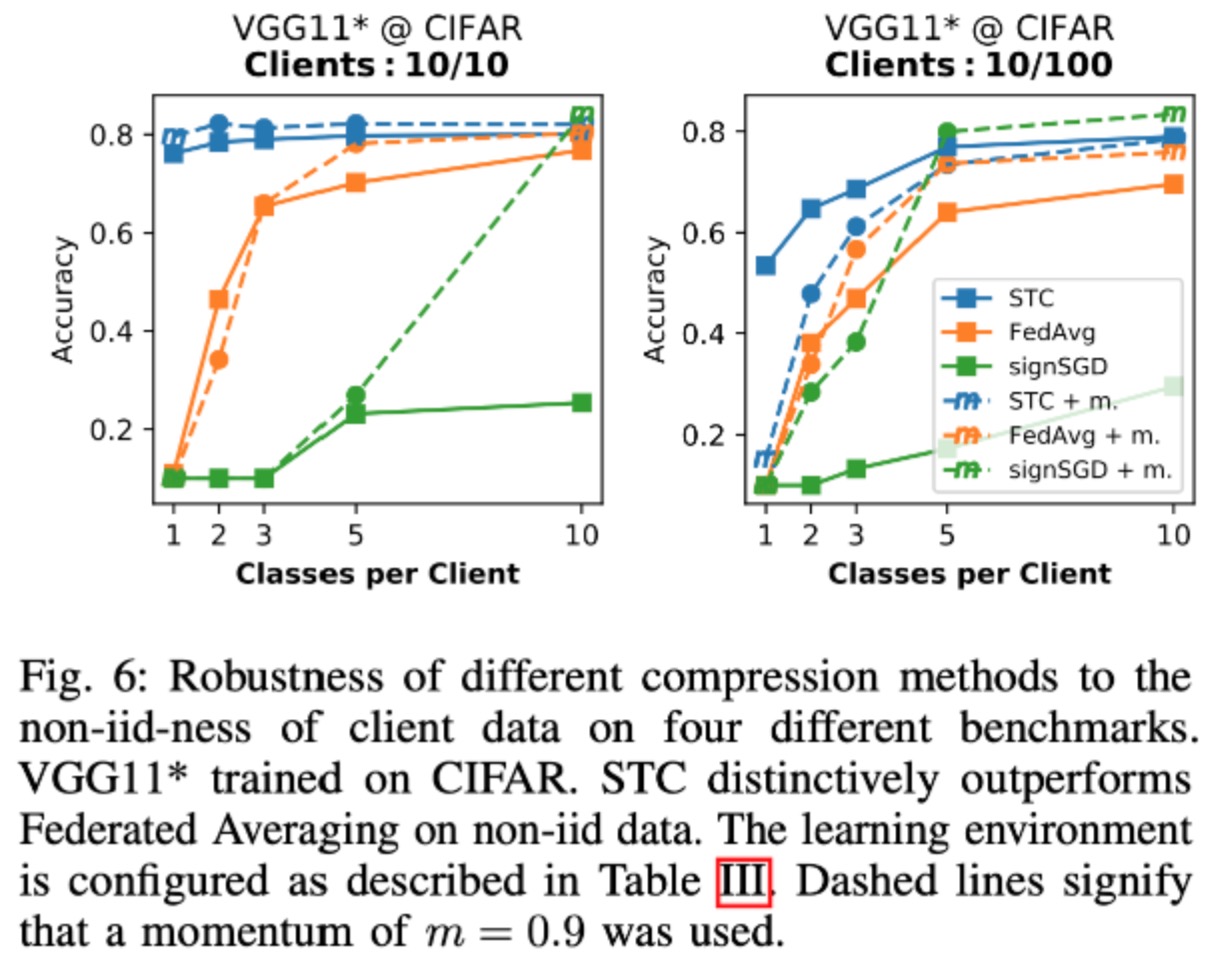
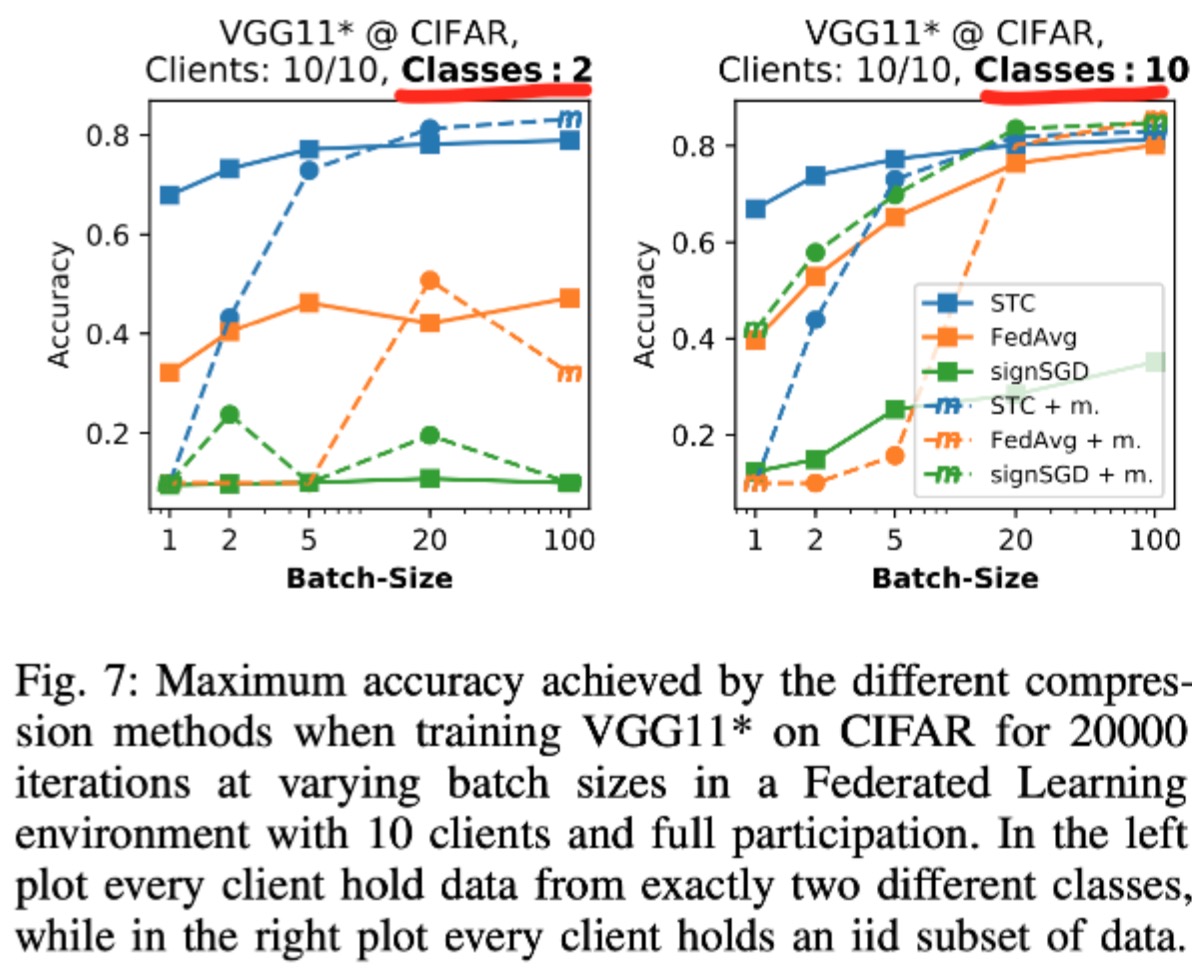
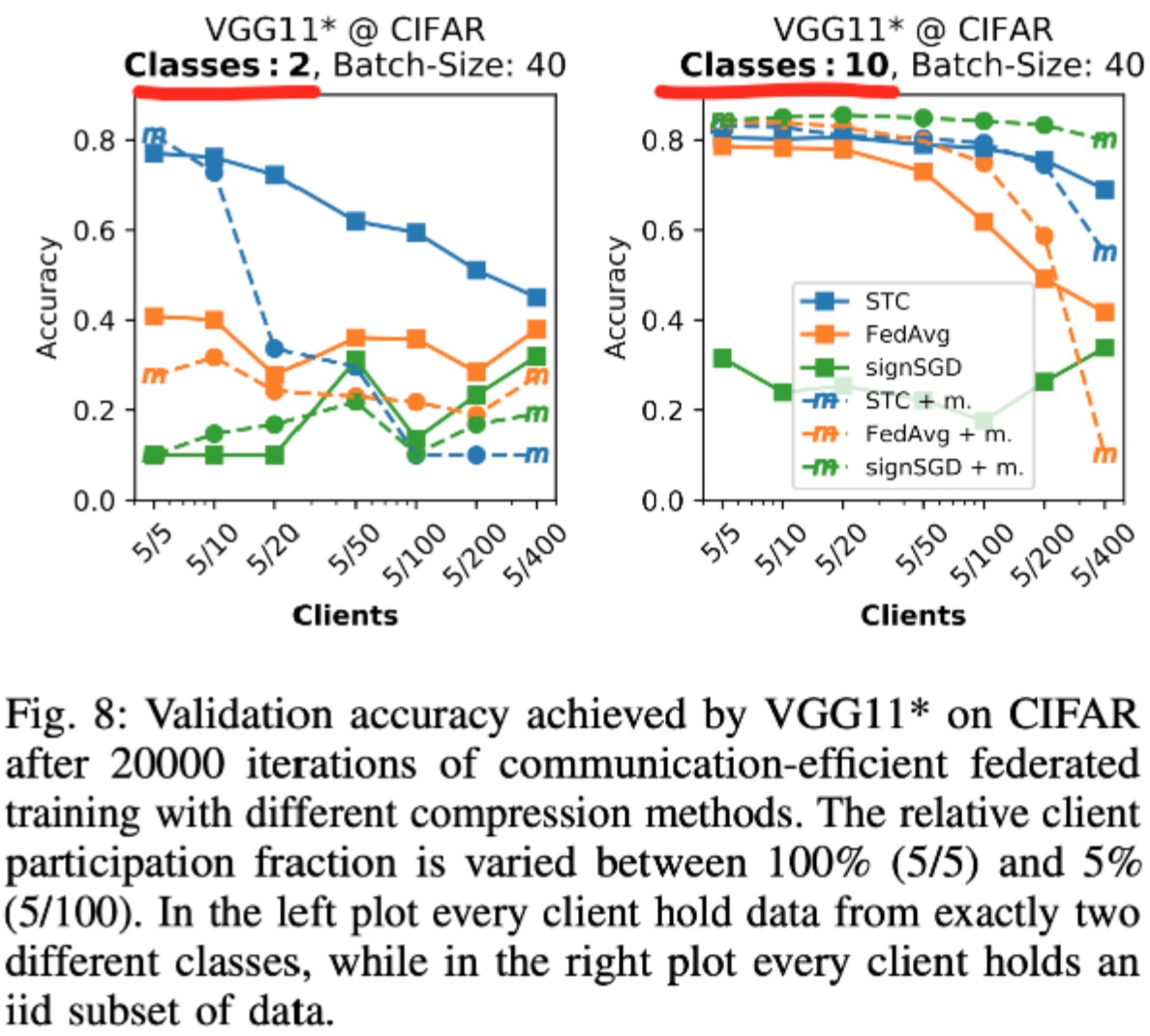
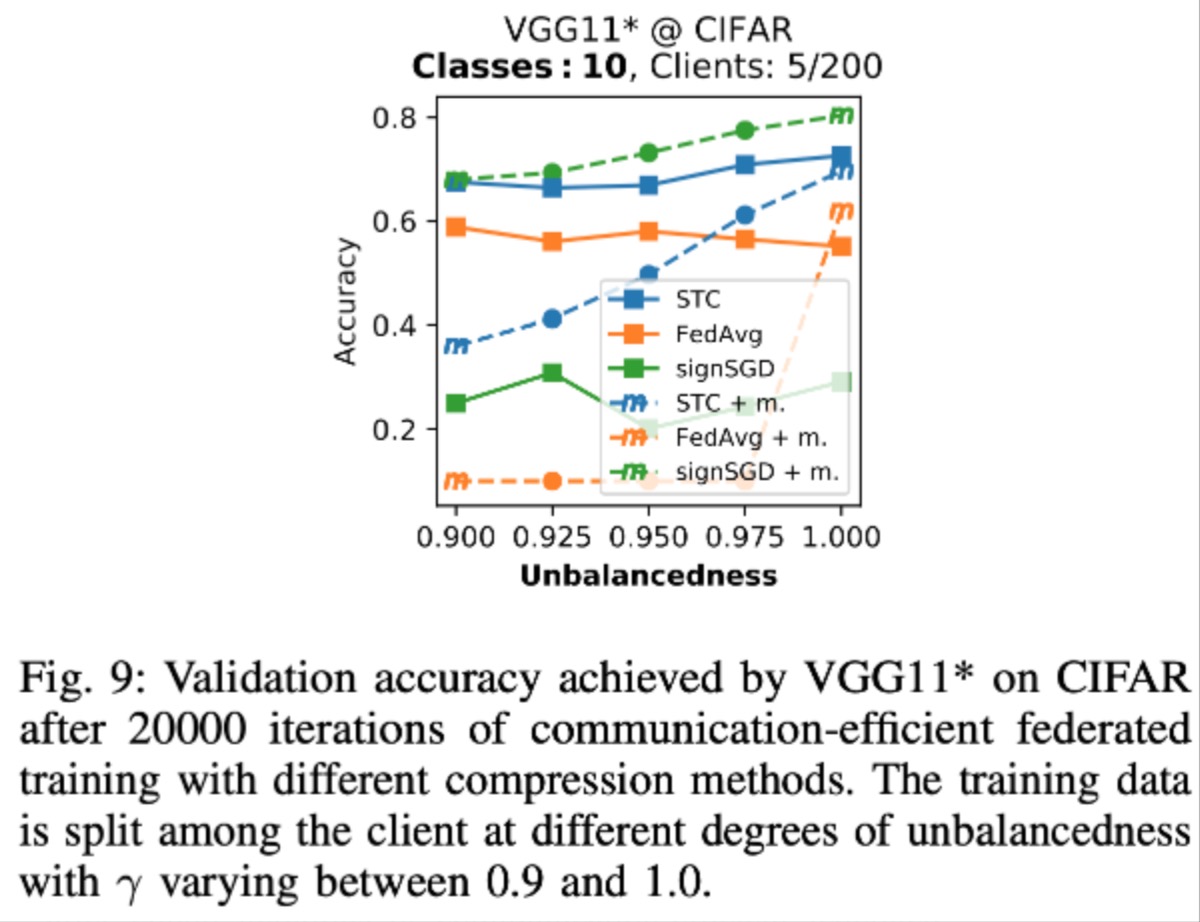
实验结论:FedSTC在(a)non-iid的情况下,(b)small batch size的情况下,(c)参与的client数量大但每轮参与度低的情况下明显比FedAvg好 |
on Non-iidness#
outperforms FedAvg#
on batch size#
on drop rate#
on data amount unbalanced#
on convergence#
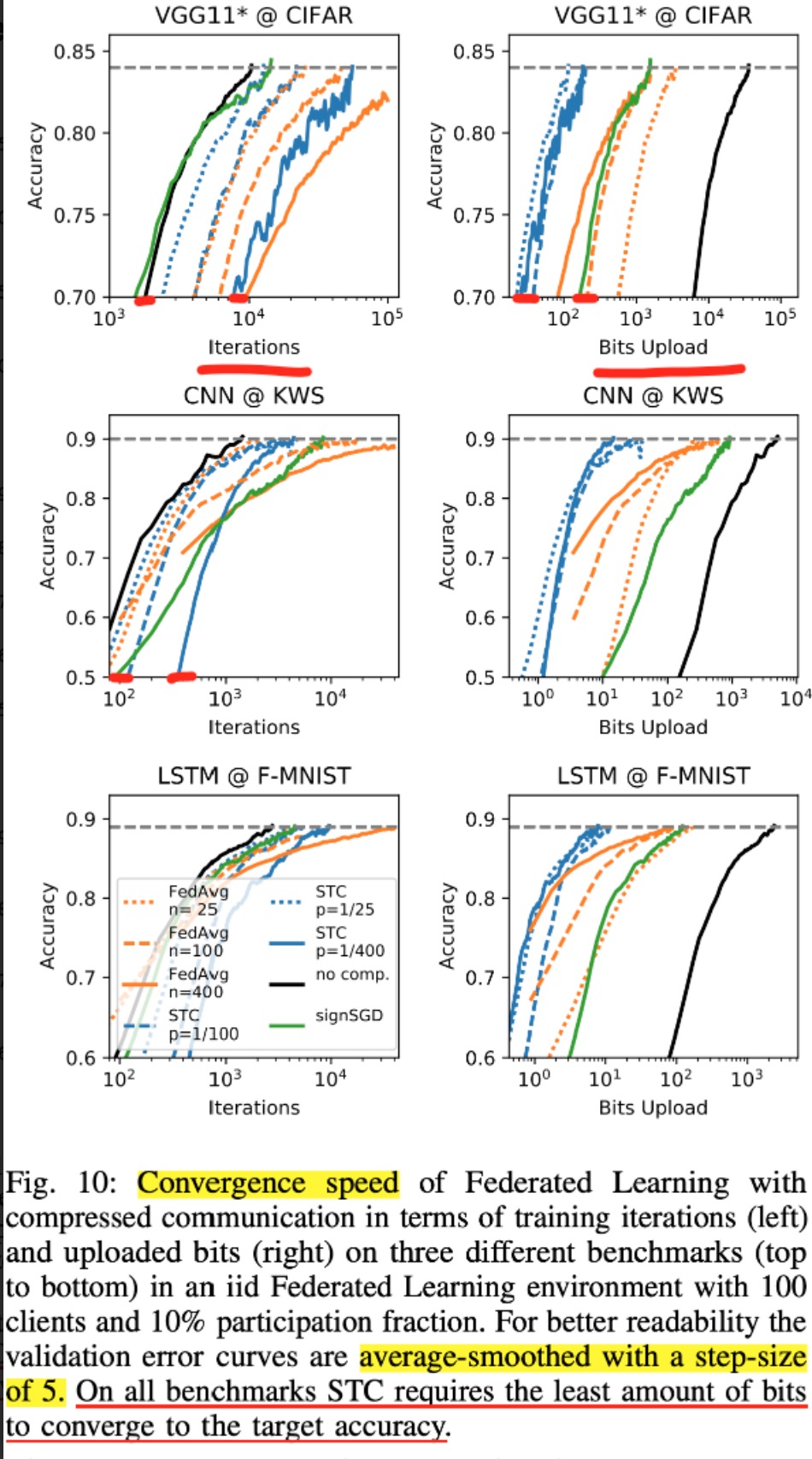
实现情况#
upstream和downstream中的sparse+binarization已经实现;
caching没有实现;
golomb/ encoding没有实现;
参考文献#
Robust and Communication-Efficient Federated Learning From Non-i.i.d. Data