SplitRec:在隐语拆分学习中使用 LabelInferenceAttack#
在联邦学习中,攻击者可以通过监听训练模型过程中传输的数值和梯度信息,攻击对方模型或数据,在一定程度上推理出有用信息,造成信息泄露。
本文考虑两方拆分学习中的标签推理攻击,将介绍论文《Label Inference Attacks Against Vertical Federated Learning》中的攻击方法在隐语中的使用。
Label Inference Attack Against Vertical Federated Learning#
论文中提出纵向联邦场景下主动和被动两种标签推理攻击方法,攻击方推测对方的样本标签造成信息泄露。

Passive Label Inference Attack through Model Completion#
被动的标签推理攻击发生在联邦模型训练之后,攻击模型推断对方标签,联邦模型训练期间不会受到干扰。
攻击模型在本地 bottom 模型(SL Model 中的 base 模型)基础上增加 top 模型使其可以预测标签。
攻击模型利用少量带标签的辅助数据和大量无标签数据,使用改进的半监督学习算法 MixMatch 进行训练。MixMatch 通过对少量标记数据和未标记数据进行数据增广,分别计算两者的损失,整体损失是两者的加权。具体改进的 MixMatch 算法如下


其中 loss 的计算公式如下
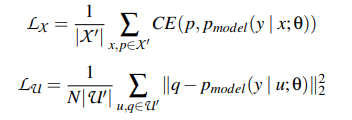
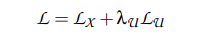
Active Label Inference Attack with the Malicious Local Optimizer#
在 Passive Label Inference Attack 基础上,恶意的攻击者可以通过使用自适应优化器扩大学习率,使 top 模型更多依赖自己的 bottom 模型,进而提高攻击的效果。
恶意优化算法如下

隐语中的攻击方法实现#
在隐语中攻击方法的实现是通过 callback 机制来完成。攻击算法基类 CallBack 位于 secretflow/ml/nn/sl/backend/torch/callback.py,我们在联邦模型训练的以下几个节点提供 hook,不同攻击方法可以通过将攻击算法实现在对应节点的 hook, 使攻击逻辑注入到联邦模型的训练过程中。
on_train_begin
on_train_end
on_epoch_begin
on_epoch_end
on_batch_begin
on_batch_end
用户如果需要实现自定义的攻击方法,需要
定义 CustomAttacker 继承基类 Callback,将攻击逻辑实现到对应的 hook 函数中
定义 attacker_builder 函数将构建 attacker 写到其中
与普通 Split Learning 模型训练一样定义 sl_model, 并在调用 sl_model.fit() 时,将 callback_dict {party -> attacker_builder} 传入 callbacks 参数即可
其中步骤 1 可以参考隐语中已有的 FeatureInferenceAttacker/LabelInferenceAttacker,步骤 2 和 3 可参考下面 LeatureInferenceAttacker 的使用方式。
Label Inferece Attack 的隐语封装#
我们在隐语中提供了多种攻击方法的封装。对于论文中的攻击方法,我们提供了 LabelInferenceAttacker 封装,具体使用可以参考以下代码。
首先和一般 Split Learning 模型训练一样,我们将进行数据处理,并定义一个 SLModel。
然后定义调用 LeatureInferenceAttacker 的 attacker_builder,并在 SLModel fit 时将 attacker_builder 传入进行训练和攻击。
环境设置#
[1]:
import secretflow as sf
# Check the version of your SecretFlow
print('The version of SecretFlow: {}'.format(sf.__version__))
# In case you have a running secretflow runtime already.
sf.shutdown()
sf.init(['alice', 'bob'], address="local")
alice, bob = sf.PYU('alice'), sf.PYU('bob')
device_y = bob
The version of SecretFlow: 1.1.0.dev20230926
2023-09-26 19:49:33,980 INFO worker.py:1538 -- Started a local Ray instance.
数据集介绍#
这里我们使用经典图像数据集 Cifar10。
这里我们对数据进行拆分,拆分模型两方各持有半张图片,攻击方不持有标签。
准备训练数据#
[2]:
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
from secretflow.data.ndarray import FedNdarray, PartitionWay
data_file_path = './data_download'
batch_size = 128
train_dataset = datasets.CIFAR10(
data_file_path, True, transform=transforms.ToTensor(), download=True
)
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False)
train_np = np.array(train_loader.dataset)
train_data = np.array([t[0].numpy() for t in train_np])
train_label = np.array([t[1] for t in train_np])
fed_data = FedNdarray(
partitions={
alice: alice(lambda x: x[:, :, :, 0:16])(train_data),
bob: bob(lambda x: x[:, :, :, 16:32])(train_data),
},
partition_way=PartitionWay.VERTICAL,
)
# party bob hold label
label = bob(lambda x: x)(train_label)
Downloading https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz to ./data_download/cifar-10-python.tar.gz
100%|██████████| 170498071/170498071 [15:08<00:00, 187619.24it/s]
Extracting ./data_download/cifar-10-python.tar.gz to ./data_download
<ipython-input-2-8b71ce40e487>:11: FutureWarning: The input object of type 'Tensor' is an array-like implementing one of the corresponding protocols (`__array__`, `__array_interface__` or `__array_struct__`); but not a sequence (or 0-D). In the future, this object will be coerced as if it was first converted using `np.array(obj)`. To retain the old behaviour, you have to either modify the type 'Tensor', or assign to an empty array created with `np.empty(correct_shape, dtype=object)`.
train_np = np.array(train_loader.dataset)
<ipython-input-2-8b71ce40e487>:11: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray.
train_np = np.array(train_loader.dataset)
定义SLModel的模型结构#
[3]:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.nn.init as init
def weights_init(m):
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight)
class LambdaLayer(nn.Module):
def __init__(self, lambd):
super(LambdaLayer, self).__init__()
self.lambd = lambd
def forward(self, x):
return self.lambd(x)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_planes, planes, kernel_size, stride=1, option='A'):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(
in_planes,
planes,
kernel_size=kernel_size,
stride=stride,
padding=1,
bias=False,
)
self.bn1 = nn.BatchNorm2d(planes)
self.conv2 = nn.Conv2d(
planes, planes, kernel_size=kernel_size, stride=1, padding=1, bias=False
)
self.bn2 = nn.BatchNorm2d(planes)
self.shortcut = nn.Sequential()
if stride != 1 or in_planes != planes:
if option == 'A':
"""
For CIFAR10 ResNet paper uses option A.
"""
self.shortcut = LambdaLayer(
lambda x: F.pad(
x[:, :, ::2, ::2],
(0, 0, 0, 0, planes // 4, planes // 4),
"constant",
0,
)
)
elif option == 'B':
self.shortcut = nn.Sequential(
nn.Conv2d(
in_planes,
self.expansion * planes,
kernel_size=1,
stride=stride,
bias=False,
),
nn.BatchNorm2d(self.expansion * planes),
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, block, num_blocks, kernel_size, num_classes):
super(ResNet, self).__init__()
self.in_planes = 16
self.conv1 = nn.Conv2d(
3, 16, kernel_size=kernel_size, stride=1, padding=1, bias=False
)
self.bn1 = nn.BatchNorm2d(16)
self.layer1 = self._make_layer(block, 16, num_blocks[0], kernel_size, stride=1)
self.layer2 = self._make_layer(block, 32, num_blocks[1], kernel_size, stride=2)
self.layer3 = self._make_layer(block, 64, num_blocks[2], kernel_size, stride=2)
self.linear = nn.Linear(64, num_classes, bias=False)
self.apply(weights_init)
def _make_layer(self, block, planes, num_blocks, kernel_size, stride):
strides = [stride] + [1] * (num_blocks - 1)
layers = []
for stride in strides:
layers.append(block(self.in_planes, planes, kernel_size, stride))
self.in_planes = planes * block.expansion
return nn.Sequential(*layers)
def forward(self, x):
# [bs,3,32,16]
out = F.relu(self.bn1(self.conv1(x)))
# [bs,16,32,16]
out = self.layer1(out)
# [bs,16,32,16]
out = self.layer2(out)
# [bs,32,16,8]
out = self.layer3(out)
# [bs,64,8,4]
out = F.avg_pool2d(out, out.size()[2:])
# [bs,64,1,1]
out = out.view(out.size(0), -1)
# [bs,64]
out = self.linear(out)
# [bs,10]
return out
def resnet20(kernel_size=(3, 3), num_classes=10):
return ResNet(
block=BasicBlock,
num_blocks=[3, 3, 3],
kernel_size=kernel_size,
num_classes=num_classes,
)
# base model
class BottomModelForCifar10(nn.Module):
def __init__(self):
super(BottomModelForCifar10, self).__init__()
self.resnet20 = resnet20(num_classes=10)
def forward(self, x):
x = self.resnet20(x)
return x
def output_num(self):
return 1
# fuse model
class TopModelForCifar10(nn.Module):
def __init__(self):
super(TopModelForCifar10, self).__init__()
self.fc1top = nn.Linear(20, 20)
self.fc2top = nn.Linear(20, 10)
self.fc3top = nn.Linear(10, 10)
self.fc4top = nn.Linear(10, 10)
self.bn0top = nn.BatchNorm1d(20)
self.bn1top = nn.BatchNorm1d(20)
self.bn2top = nn.BatchNorm1d(10)
self.bn3top = nn.BatchNorm1d(10)
print('batch norm: ', self.bn0top)
self.apply(weights_init)
def forward(self, input_tensor):
output_bottom_models = torch.cat(input_tensor, dim=1)
x = output_bottom_models
x = self.fc1top(F.relu(self.bn0top(x)))
x = self.bn1top(x)
x = self.fc2top(F.relu(x))
x = self.fc3top(F.relu(self.bn2top(x)))
x = self.fc4top(F.relu(self.bn3top(x)))
return F.log_softmax(x, dim=1)
定义SLModel#
[4]:
import torch.optim as optim
from secretflow.ml.nn.utils import TorchModel
from torchmetrics import Accuracy, Precision
from secretflow.ml.nn import SLModel
from secretflow.ml.nn.fl.utils import metric_wrapper, optim_wrapper
loss_fn = nn.CrossEntropyLoss
optim_fn = optim_wrapper(optim.SGD, lr=1e-2, momentum=0.9, weight_decay=5e-4)
base_model = TorchModel(
model_fn=BottomModelForCifar10,
loss_fn=loss_fn,
optim_fn=optim_fn,
metrics=[
metric_wrapper(Accuracy, task="multiclass", num_classes=10, average='micro'),
metric_wrapper(Precision, task="multiclass", num_classes=10, average='micro'),
],
)
fuse_model = TorchModel(
model_fn=TopModelForCifar10,
loss_fn=loss_fn,
optim_fn=optim_fn,
metrics=[
metric_wrapper(Accuracy, task="multiclass", num_classes=10, average='micro'),
metric_wrapper(Precision, task="multiclass", num_classes=10, average='micro'),
],
)
base_model_dict = {
alice: base_model,
bob: base_model,
}
sl_model = SLModel(
base_model_dict=base_model_dict,
device_y=device_y,
model_fuse=fuse_model,
dp_strategy_dict=None,
compressor=None,
simulation=True,
random_seed=1234,
backend='torch',
strategy='split_nn',
)
INFO:root:Create proxy actor <class 'secretflow.ml.nn.sl.backend.torch.strategy.split_nn.PYUSLTorchModel'> with party alice.
INFO:root:Create proxy actor <class 'secretflow.ml.nn.sl.backend.torch.strategy.split_nn.PYUSLTorchModel'> with party bob.
定义 attacker_builder#
定义 Attacker 模型结构#
这里 Attacker 模型是在原 base 模型(BottomModelForCifar10)基础上加一个 top 模型,这里只需定义 top 模型 BottomModelPlus
[5]:
import torch.nn as nn
def weights_init_ones(m):
if isinstance(m, nn.Linear) or isinstance(m, nn.Conv2d):
init.ones_(m.weight)
# for attacker
class BottomModelPlus(nn.Module):
def __init__(
self,
bottom_model,
size_bottom_out=10,
num_classes=10,
num_layer=1,
activation_func_type='ReLU',
use_bn=True,
):
super(BottomModelPlus, self).__init__()
self.bottom_model = bottom_model
dict_activation_func_type = {'ReLU': F.relu, 'Sigmoid': F.sigmoid, 'None': None}
self.activation_func = dict_activation_func_type[activation_func_type]
self.num_layer = num_layer
self.use_bn = use_bn
self.fc_1 = nn.Linear(size_bottom_out, size_bottom_out, bias=True)
self.bn_1 = nn.BatchNorm1d(size_bottom_out)
self.fc_1.apply(weights_init_ones)
self.fc_2 = nn.Linear(size_bottom_out, size_bottom_out, bias=True)
self.bn_2 = nn.BatchNorm1d(size_bottom_out)
self.fc_2.apply(weights_init_ones)
self.fc_3 = nn.Linear(size_bottom_out, size_bottom_out, bias=True)
self.bn_3 = nn.BatchNorm1d(size_bottom_out)
self.fc_3.apply(weights_init_ones)
self.fc_4 = nn.Linear(size_bottom_out, size_bottom_out, bias=True)
self.bn_4 = nn.BatchNorm1d(size_bottom_out)
self.fc_4.apply(weights_init_ones)
self.fc_final = nn.Linear(size_bottom_out, num_classes, bias=True)
self.bn_final = nn.BatchNorm1d(size_bottom_out)
self.fc_final.apply(weights_init_ones)
def forward(self, x):
x = self.bottom_model(x)
if self.num_layer >= 2:
if self.use_bn:
x = self.bn_1(x)
if self.activation_func:
x = self.activation_func(x)
x = self.fc_1(x)
if self.num_layer >= 3:
if self.use_bn:
x = self.bn_2(x)
if self.activation_func:
x = self.activation_func(x)
x = self.fc_2(x)
if self.num_layer >= 4:
if self.use_bn:
x = self.bn_3(x)
if self.activation_func:
x = self.activation_func(x)
x = self.fc_3(x)
if self.num_layer >= 5:
if self.use_bn:
x = self.bn_4(x)
if self.activation_func:
x = self.activation_func(x)
x = self.fc_4(x)
if self.use_bn:
x = self.bn_final(x)
if self.activation_func:
x = self.activation_func(x)
x = self.fc_final(x)
return x
定义 Attacker 需要的数据#
这里标签攻击算法需要少量有标签的辅助数据集,及本身的大量无标签数据。
[6]:
import torch
from torchvision import datasets, transforms
class CIFAR10Labeled(datasets.CIFAR10):
def __init__(
self,
root,
indexs=None,
train=True,
transform=None,
target_transform=None,
download=False,
):
super(CIFAR10Labeled, self).__init__(
root,
train=train,
transform=transform,
target_transform=target_transform,
download=download,
)
if indexs is not None:
self.data = self.data[indexs]
self.targets = np.array(self.targets)[indexs]
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], self.targets[index]
if self.transform is not None:
img = self.transform(img)
img = img[:, :, :16]
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
class CIFAR10Unlabeled(CIFAR10Labeled):
def __init__(
self,
root,
indexs,
train=True,
transform=None,
target_transform=None,
download=False,
):
super(CIFAR10Unlabeled, self).__init__(
root,
indexs,
train=train,
transform=transform,
target_transform=target_transform,
download=download,
)
self.targets = np.array([-1 for i in range(len(self.targets))])
self.data = self.data[:, :, :, :16]
def label_index_split(labels, n_labeled_per_class, num_classes):
labels = np.array(labels)
train_labeled_idxs = []
train_unlabeled_idxs = []
for i in range(num_classes):
idxs = np.where(labels == i)[0]
np.random.shuffle(idxs)
train_labeled_idxs.extend(idxs[:n_labeled_per_class])
train_unlabeled_idxs.extend(idxs[n_labeled_per_class:])
np.random.shuffle(train_labeled_idxs)
np.random.shuffle(train_unlabeled_idxs)
return train_labeled_idxs, train_unlabeled_idxs
def data_builder(batch_size, file_path=None):
def prepare_data():
n_labeled = 40
num_classes = 10
def get_transforms():
transform_ = transforms.Compose(
[
transforms.ToTensor(),
]
)
return transform_
transforms_ = get_transforms()
base_dataset = datasets.CIFAR10(file_path, train=True)
train_labeled_idxs, train_unlabeled_idxs = label_index_split(
base_dataset.targets, int(n_labeled / num_classes), num_classes
)
train_labeled_dataset = CIFAR10Labeled(
file_path, train_labeled_idxs, train=True, transform=transforms_
)
train_unlabeled_dataset = CIFAR10Unlabeled(
file_path, train_unlabeled_idxs, train=True, transform=transforms_
)
train_complete_dataset = CIFAR10Labeled(
file_path, None, train=True, transform=transforms_
)
test_dataset = CIFAR10Labeled(
file_path, train=False, transform=transforms_, download=True
)
print(
"#Labeled:",
len(train_labeled_idxs),
"#Unlabeled:",
len(train_unlabeled_idxs),
)
# auxiliary dataset
labeled_trainloader = torch.utils.data.DataLoader(
train_labeled_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0,
drop_last=True,
)
unlabeled_trainloader = torch.utils.data.DataLoader(
train_unlabeled_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0,
drop_last=True,
)
dataset_bs = batch_size * 10
test_loader = torch.utils.data.DataLoader(
test_dataset, batch_size=dataset_bs, shuffle=False, num_workers=0
)
train_complete_trainloader = torch.utils.data.DataLoader(
train_complete_dataset,
batch_size=dataset_bs,
shuffle=False,
num_workers=0,
drop_last=True,
)
return (
labeled_trainloader,
unlabeled_trainloader,
test_loader,
train_complete_trainloader,
)
return prepare_data
定义 attacker_builder#
这里 attacker_builder 是一个字典,其元素是参与方和对应的 attacker_builder,通常只需要填充攻击方和对应的 attacker_builder_function。
本文中 Label Inference Attack 只需填充攻击方 alice 和对应的 attacker_builder_function。
[7]:
from secretflow.ml.nn.sl.attacks.lia_torch import (
LabelInferenceAttacker,
)
def create_attacker_builder(file_path, batch_size, model_save_path):
def attacker_builder():
def create_model(ema=False):
bottom_model = BottomModelForCifar10()
model = BottomModelPlus(bottom_model)
if ema:
for param in model.parameters():
param.detach_()
return model
model = create_model(ema=False)
ema_model = create_model(ema=True)
data_buil = data_builder(batch_size=batch_size, file_path=file_path)
attacker = LabelInferenceAttacker(
model, ema_model, 10, data_buil, save_model_path=model_save_path
)
return attacker
return attacker_builder
callback_dict = {
alice: create_attacker_builder(
file_path=data_file_path, batch_size=16, model_save_path=None
)
}
开始训练和攻击#
[8]:
history = sl_model.fit(
fed_data,
label,
validation_data=(fed_data, label),
epochs=1,
batch_size=128,
shuffle=False,
random_seed=1234,
dataset_builder=None,
# callbacks=callback_dict, # 暂时注释掉,callback完成后恢复 @caibei
)
print(history)
INFO:root:SL Train Params: {'x': FedNdarray(partitions={PYURuntime(alice): <secretflow.device.device.pyu.PYUObject object at 0x7f3728683280>, PYURuntime(bob): <secretflow.device.device.pyu.PYUObject object at 0x7f372336a250>}, partition_way=<PartitionWay.VERTICAL: 'vertical'>), 'y': <secretflow.device.device.pyu.PYUObject object at 0x7f372336a8b0>, 'batch_size': 128, 'epochs': 1, 'verbose': 1, 'callbacks': {PYURuntime(alice): <function create_attacker_builder.<locals>.attacker_builder at 0x7f36ca5eb9d0>}, 'validation_data': (FedNdarray(partitions={PYURuntime(alice): <secretflow.device.device.pyu.PYUObject object at 0x7f3728683280>, PYURuntime(bob): <secretflow.device.device.pyu.PYUObject object at 0x7f372336a250>}, partition_way=<PartitionWay.VERTICAL: 'vertical'>), <secretflow.device.device.pyu.PYUObject object at 0x7f372336a8b0>), 'shuffle': False, 'sample_weight': None, 'validation_freq': 1, 'dp_spent_step_freq': None, 'dataset_builder': None, 'audit_log_params': {}, 'random_seed': 1234, 'audit_log_dir': None, 'self': <secretflow.ml.nn.sl.sl_model.SLModel object at 0x7f3712ff94c0>}
(pid=1866347) 2023-09-26 20:05:02.902472: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(pid=1866419) 2023-09-26 20:05:03.037969: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(pid=1866347) 2023-09-26 20:05:03.744462: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(pid=1866347) 2023-09-26 20:05:03.744559: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(pid=1866347) 2023-09-26 20:05:03.744571: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
(pid=1866419) 2023-09-26 20:05:03.855912: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(pid=1866419) 2023-09-26 20:05:03.856003: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(pid=1866419) 2023-09-26 20:05:03.856014: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
(PYUSLTorchModel pid=1866419) batch norm: BatchNorm1d(20, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
1%| | 2/391 [00:00<00:45, 8.53it/s](_run pid=1826653) 2023-09-26 20:05:07.309229: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(_run pid=1826653) 2023-09-26 20:05:08.016360: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(_run pid=1826653) 2023-09-26 20:05:08.016462: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(_run pid=1826653) 2023-09-26 20:05:08.016475: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
26%|██▌ | 102/391 [00:46<01:59, 2.43it/s](_run pid=1826989) 2023-09-26 20:05:53.319477: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(_run pid=1826989) 2023-09-26 20:05:54.012634: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(_run pid=1826989) 2023-09-26 20:05:54.012721: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/gcc-toolset-11/root/usr/lib64:/opt/rh/gcc-toolset-11/root/usr/lib:/opt/rh/gcc-toolset-11/root/usr/lib64/dyninst:/opt/rh/gcc-toolset-11/root/usr/lib/dyninst
(_run pid=1826989) 2023-09-26 20:05:54.012732: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
100%|██████████| 391/391 [02:53<00:00, 2.31it/s](PYUSLTorchModel pid=1866419) /home/ssd2/zhaocaibei/miniconda3/envs/jupyter/lib/python3.8/site-packages/secretflow/ml/nn/sl/backend/torch/sl_base.py:627: UserWarning: The given NumPy array is not writable, and PyTorch does not support non-writable tensors. This means writing to this tensor will result in undefined behavior. You may want to copy the array to protect its data or make it writable before converting it to a tensor. This type of warning will be suppressed for the rest of this program. (Triggered internally at ../torch/csrc/utils/tensor_numpy.cpp:206.)
(PYUSLTorchModel pid=1866419) torch.as_tensor(e)
100%|██████████| 391/391 [03:40<00:00, 1.78it/s, epoch: 1/1 - train_loss:1.6854610443115234 train_MulticlassAccuracy:0.300819993019104 train_MulticlassPrecision:0.300819993019104 val_val_loss:1.873559594154358 val_MulticlassAccuracy:0.36000001430511475 val_MulticlassPrecision:0.36000001430511475 ]
(PYUSLTorchModel pid=1866347) Files already downloaded and verified
(PYUSLTorchModel pid=1866347) INFO:root:Epoch: [1 | 1]
(PYUSLTorchModel pid=1866347) #Labeled: 40 #Unlabeled: 49960
(PYUSLTorchModel pid=1866347) INFO:root:batch_idx: 0, loss: 2.3291807174682617
(PYUSLTorchModel pid=1866347) INFO:root:batch_idx: 250, loss: 2.070810818102255
(PYUSLTorchModel pid=1866347) INFO:root:batch_idx: 500, loss: 2.002920127676395
(PYUSLTorchModel pid=1866347) INFO:root:batch_idx: 750, loss: 1.998070199226095
(PYUSLTorchModel pid=1866347) INFO:root:batch_idx: 1000, loss: 2.016154585303841
(PYUSLTorchModel pid=1866347) INFO:root:---Label inference on evaluation dataset 0
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 0
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 50
(PYUSLTorchModel pid=1866347) INFO:root:Dataset Overall Statistics:
(PYUSLTorchModel pid=1866347) INFO:root:top 1 accuracy:23.77, top 4 accuracy:66.64
(PYUSLTorchModel pid=1866347) INFO:root:evaluate metric 0, 0.23770000040531158
(PYUSLTorchModel pid=1866347) INFO:root:evaluate metric 1, 0.23770000040531158
(PYUSLTorchModel pid=1866347) INFO:root:test_loss: 2.0509094161987305, test_acc: 23.77
(PYUSLTorchModel pid=1866347) INFO:root:---Label inference on evaluation dataset 1
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 0
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 50
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 100
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 150
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 200
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 250
(PYUSLTorchModel pid=1866347) INFO:root:evaluate 300
{'train_loss': [array(1.685461, dtype=float32)], 'train_MulticlassAccuracy': [tensor(0.3008)], 'train_MulticlassPrecision': [tensor(0.3008)], 'val_val_loss': [array(1.8735596, dtype=float32)], 'val_MulticlassAccuracy': [tensor(0.3600)], 'val_MulticlassPrecision': [tensor(0.3600)]}
总结#
本文通过 Cifar10 数据集上的标签推理攻击任务来演示如何通过隐语来使用 LabelInferenceAttack。
您可以:
下载并拆分数据集,准备训练、攻击使用的数据
定义拆分模型结构及 SL Model
定义 attacker_builder,在其中定义攻击需要的 data_builder 和 LabelInfereceAttacker
调用 SL Model 进行训练攻击
您可以在自己的数据集上进行尝试,如有任何问题,可以在 github 进行训练即可。