SplitRec:在隐语中使用拆分 DeepFM 算法(Tensorflow 后端)#
以下代码仅作为示例,请勿在生产环境直接使用。
[1]:
%load_ext autoreload
%autoreload 2
隐语在垂直场景提供了SLModel来满足用户的垂直联邦需求,垂直场景中,各方通过特征互补,联合训练来达到训练出更好模型的目的。而在实际的应用场景中,推荐场景和垂直联邦方案非常契合。有很大的应用前景。 不同的数据持有方拥有不同的特征,彼此不愿意分享,但是特征之间是互补的,比如消费特征、金融特征和用户画像等。但是推荐算法往往并不是那么直接可以被应用到拆分学习中,比如FM算法需要特征交叉。 因此我们在隐语中提供了一个专项,通过对常用的推荐算法进行封装,来达到方便用户使用联邦学习进行推荐应用的目的。 本文下面将会介绍何在隐语中使用DeepFM算法
DeepFM拆分原理介绍#
DeepFM算法结合了FM和神经网络的长处,可以同时提升低维和高维特征,相比Wide&Deep模型还免去了特征工程的部分。
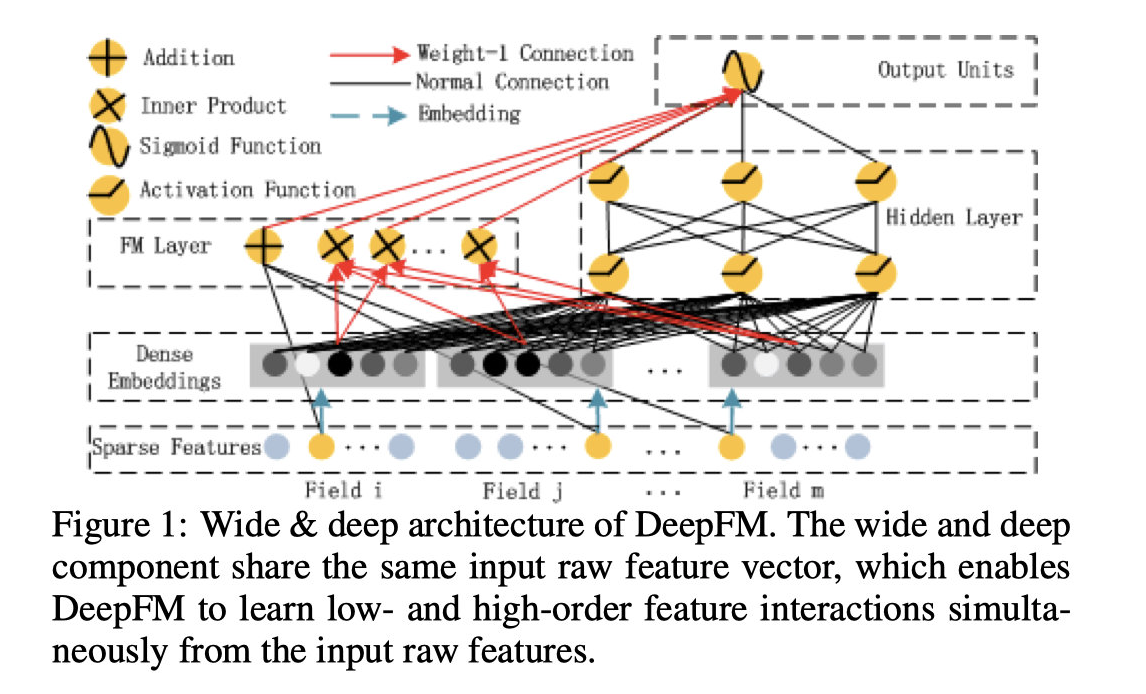
整体上来看。这个模型可以分成两个部分,分别是FM部分以及Deep部分。这两个部分的输入是一样的,并没有像Wide & Deep模型那样做区分。Deep的部分用来训练这些特征的高维的关联,而FM模型会通过隐藏向量V的形式来计算特征之间的二维交叉的信息。
隐语中的DeepFM#
拆分方案
DeepFM公式推导
进行数学化简
最终得到公式
DeepFM拆分版本#
从上面的公式推导可以看出,FM的计算中消去了$V_j$
所以问题就转成了只要每方计算好自己的 $sum_{i}^kViX$ 和 $sum_{i}^kV_i^2X^2$ 继续对这个公式进行化简得到
\[\hat{y}=w_0+\sum_{i=1}^nw_ix_i +\frac{1}{2}[\sum_{f=1}^k(\sum_{i=1}^nV_{i,f}x_i)^2 - \sum_{f=1}^k\sum_{i=1}^nV_{i,f}^2{x_i}^2]\]
从公式推导中可以看出,对于每一方参与者只需要在本地算出一阶$sum_{i=1}^aV_{i,f}x_i$和$sum_{i=1}^aV_{i,f}^2{x_i}^2$ 然后传输(1)和(2)两部分到fusenet即可完成无损的fm部分计算

隐语封装#
class DeepFMbase(tf.keras.Model):
def __init__(
self,
dnn_units_size,
dnn_activation="relu",
preprocess_layer=None,
fm_embedding_dim=16,
**kwargs,
):
"""Split learning version of DeepFM
Args:
dnn_units_size: list,list of positive integer or empty list, the layer number and units in each layer of DNN
dnn_activation: activation function of dnn part
preprocess_layer: The preprocessed layer a keras model, output a dict of preprocessed data
fm_embedding_dim: fm embedding dim, default to be 16
DeepFMFuse
class DeepFMfuse(tf.keras.Model):
def __init__(self, dnn_units_size, dnn_activation="relu", **kwargs):
下面我们通过一个例子来看一下如果使用隐语封装的DeepFM来进行训练和预测
环境设置#
[2]:
import secretflow as sf
# Check the version of your SecretFlow
print('The version of SecretFlow: {}'.format(sf.__version__))
# In case you have a running secretflow runtime already.
sf.shutdown()
sf.init(['alice', 'bob', 'charlie'], address="local", log_to_driver=False)
alice, bob, charlie = sf.PYU('alice'), sf.PYU('bob'), sf.PYU('charlie')
The version of SecretFlow: 1.0.0a0
2023-07-25 11:26:15,683 INFO worker.py:1538 -- Started a local Ray instance.
数据集介绍#
DataBuilder相关的细节内容,请查看CustomDataLoaderOnSL
下载并处理数据#
数据拆分处理
[3]:
%%capture
%%!
wget https://secretflow-data.oss-accelerate.aliyuncs.com/datasets/movielens/ml-1m.zip
unzip ./ml-1m.zip
[4]:
# Read the data in dat format and convert it into a dictionary
def load_data(filename, columns):
data = {}
with open(filename, "r", encoding="unicode_escape") as f:
for line in f:
ls = line.strip("\n").split("::")
data[ls[0]] = dict(zip(columns[1:], ls[1:]))
return data
[5]:
fed_csv = {alice: "alice_ml1m.csv", bob: "bob_ml1m.csv"}
csv_writer_container = {alice: open(fed_csv[alice], "w"), bob: open(fed_csv[bob], "w")}
part_columns = {
alice: ["UserID", "Gender", "Age", "Occupation", "Zip-code"],
bob: ["MovieID", "Rating", "Title", "Genres", "Timestamp"],
}
[6]:
for device, writer in csv_writer_container.items():
writer.write("ID," + ",".join(part_columns[device]) + "\n")
[7]:
f = open("ml-1m/ratings.dat", "r", encoding="unicode_escape")
users_data = load_data(
"./ml-1m/users.dat",
columns=["UserID", "Gender", "Age", "Occupation", "Zip-code"],
)
movies_data = load_data("./ml-1m/movies.dat", columns=["MovieID", "Title", "Genres"])
ratings_columns = ["UserID", "MovieID", "Rating", "Timestamp"]
rating_data = load_data("./ml-1m/ratings.dat", columns=ratings_columns)
def _parse_example(feature, columns, index):
if "Title" in feature.keys():
feature["Title"] = feature["Title"].replace(",", "_")
if "Genres" in feature.keys():
feature["Genres"] = feature["Genres"].replace("|", " ")
values = []
values.append(str(index))
for c in columns:
values.append(feature[c])
return ",".join(values)
index = 0
num_sample = 1000
for line in f:
ls = line.strip().split("::")
rating = dict(zip(ratings_columns, ls))
rating.update(users_data.get(ls[0]))
rating.update(movies_data.get(ls[1]))
for device, columns in part_columns.items():
parse_f = _parse_example(rating, columns, index)
csv_writer_container[device].write(parse_f + "\n")
index += 1
if num_sample > 0 and index >= num_sample:
break
for w in csv_writer_container.values():
w.close()
到此为止我们已经完成了数据的处理和拆分#
产出了
alice: alice_ml1m.csv
bob: bob_ml1m.csv
[8]:
! head alice_ml1m.csv
ID,UserID,Gender,Age,Occupation,Zip-code
0,1,F,1,10,48067
1,1,F,1,10,48067
2,1,F,1,10,48067
3,1,F,1,10,48067
4,1,F,1,10,48067
5,1,F,1,10,48067
6,1,F,1,10,48067
7,1,F,1,10,48067
8,1,F,1,10,48067
[9]:
! head bob_ml1m.csv
ID,MovieID,Rating,Title,Genres,Timestamp
0,1193,5,One Flew Over the Cuckoo's Nest (1975),Drama,978300760
1,661,3,James and the Giant Peach (1996),Animation Children's Musical,978302109
2,914,3,My Fair Lady (1964),Musical Romance,978301968
3,3408,4,Erin Brockovich (2000),Drama,978300275
4,2355,5,Bug's Life_ A (1998),Animation Children's Comedy,978824291
5,1197,3,Princess Bride_ The (1987),Action Adventure Comedy Romance,978302268
6,1287,5,Ben-Hur (1959),Action Adventure Drama,978302039
7,2804,5,Christmas Story_ A (1983),Comedy Drama,978300719
8,594,4,Snow White and the Seven Dwarfs (1937),Animation Children's Musical,978302268
构造data_builder_dict#
[10]:
# alice
def create_dataset_builder_alice(
batch_size=128,
repeat_count=5,
):
def dataset_builder(x):
import pandas as pd
import tensorflow as tf
x = [dict(t) if isinstance(t, pd.DataFrame) else t for t in x]
x = x[0] if len(x) == 1 else tuple(x)
data_set = (
tf.data.Dataset.from_tensor_slices(x).batch(batch_size).repeat(repeat_count)
)
return data_set
return dataset_builder
# bob
def create_dataset_builder_bob(
batch_size=128,
repeat_count=5,
):
def _parse_bob(row_sample, label):
import tensorflow as tf
y_t = label["Rating"]
y = tf.expand_dims(
tf.where(
y_t > 3,
tf.ones_like(y_t, dtype=tf.float32),
tf.zeros_like(y_t, dtype=tf.float32),
),
axis=1,
)
return row_sample, y
def dataset_builder(x):
import pandas as pd
import tensorflow as tf
x = [dict(t) if isinstance(t, pd.DataFrame) else t for t in x]
x = x[0] if len(x) == 1 else tuple(x)
data_set = (
tf.data.Dataset.from_tensor_slices(x).batch(batch_size).repeat(repeat_count)
)
data_set = data_set.map(_parse_bob)
return data_set
return dataset_builder
data_builder_dict = {
alice: create_dataset_builder_alice(
batch_size=128,
repeat_count=5,
),
bob: create_dataset_builder_bob(
batch_size=128,
repeat_count=5,
),
}
[ ]:
# Use the packaged DeepFMBase and DeepFMFuse to define the model
[11]:
from secretflow.ml.nn.applications.sl_deep_fm import DeepFMbase, DeepFMfuse
from secretflow.ml.nn import SLModel
NUM_USERS = 6040
NUM_MOVIES = 3952
GENDER_VOCAB = ["F", "M"]
AGE_VOCAB = [1, 18, 25, 35, 45, 50, 56]
OCCUPATION_VOCAB = [i for i in range(21)]
GENRES_VOCAB = [
"Action",
"Adventure",
"Animation",
"Children's",
"Comedy",
"Crime",
"Documentary",
"Drama",
"Fantasy",
"Film-Noir",
"Horror",
"Musical",
"Mystery",
"Romance",
"Sci-Fi",
"Thriller",
"War",
"Western",
]
2023-07-25 11:26:23.897995: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/devtoolset-11/root/usr/lib64:/opt/rh/devtoolset-11/root/usr/lib:/opt/rh/devtoolset-11/root/usr/lib64/dyninst:/opt/rh/devtoolset-11/root/usr/lib/dyninst
2023-07-25 11:26:24.839817: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/devtoolset-11/root/usr/lib64:/opt/rh/devtoolset-11/root/usr/lib:/opt/rh/devtoolset-11/root/usr/lib64/dyninst:/opt/rh/devtoolset-11/root/usr/lib/dyninst
2023-07-25 11:26:24.839928: W tensorflow/compiler/xla/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/devtoolset-11/root/usr/lib64:/opt/rh/devtoolset-11/root/usr/lib:/opt/rh/devtoolset-11/root/usr/lib64/dyninst:/opt/rh/devtoolset-11/root/usr/lib/dyninst
2023-07-25 11:26:24.839940: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
[12]:
# Define alice's basenet
def create_base_model_alice():
# Create model
def create_model():
import tensorflow as tf
def preprocess():
inputs = {
"UserID": tf.keras.Input(shape=(1,), dtype=tf.string),
"Gender": tf.keras.Input(shape=(1,), dtype=tf.string),
"Age": tf.keras.Input(shape=(1,), dtype=tf.int64),
"Occupation": tf.keras.Input(shape=(1,), dtype=tf.int64),
}
user_id_output = tf.keras.layers.Hashing(
num_bins=NUM_USERS, output_mode="one_hot"
)
user_gender_output = tf.keras.layers.StringLookup(
vocabulary=GENDER_VOCAB, output_mode="one_hot"
)
user_age_out = tf.keras.layers.IntegerLookup(
vocabulary=AGE_VOCAB, output_mode="one_hot"
)
user_occupation_out = tf.keras.layers.IntegerLookup(
vocabulary=OCCUPATION_VOCAB, output_mode="one_hot"
)
outputs = {
"UserID": user_id_output(inputs["UserID"]),
"Gender": user_gender_output(inputs["Gender"]),
"Age": user_age_out(inputs["Age"]),
"Occupation": user_occupation_out(inputs["Occupation"]),
}
return tf.keras.Model(inputs=inputs, outputs=outputs)
preprocess_layer = preprocess()
model = DeepFMbase(
dnn_units_size=[256, 32],
preprocess_layer=preprocess_layer,
)
model.compile(
loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[
tf.keras.metrics.AUC(),
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
],
)
return model # need wrap
return create_model
[13]:
# Define bob's basenet
def create_base_model_bob():
# Create model
def create_model():
import tensorflow as tf
# define preprocess layer
def preprocess():
inputs = {
"MovieID": tf.keras.Input(shape=(1,), dtype=tf.string),
"Genres": tf.keras.Input(shape=(1,), dtype=tf.string),
}
movie_id_out = tf.keras.layers.Hashing(
num_bins=NUM_MOVIES, output_mode="one_hot"
)
movie_genres_out = tf.keras.layers.TextVectorization(
output_mode='multi_hot', split="whitespace", vocabulary=GENRES_VOCAB
)
outputs = {
"MovieID": movie_id_out(inputs["MovieID"]),
"Genres": movie_genres_out(inputs["Genres"]),
}
return tf.keras.Model(inputs=inputs, outputs=outputs)
preprocess_layer = preprocess()
model = DeepFMbase(
dnn_units_size=[256, 32],
preprocess_layer=preprocess_layer,
)
model.compile(
loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[
tf.keras.metrics.AUC(),
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
],
)
return model # need wrap
return create_model
定义Fusenet#
[14]:
def create_fuse_model():
# Create model
def create_model():
import tensorflow as tf
model = DeepFMfuse(dnn_units_size=[256, 256, 32])
model.compile(
loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=[
tf.keras.metrics.AUC(),
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
],
)
return model
return create_model
[15]:
base_model_dict = {alice: create_base_model_alice(), bob: create_base_model_bob()}
model_fuse = create_fuse_model()
运行起来看看#
[16]:
from secretflow.data.vertical import read_csv as v_read_csv
vdf = v_read_csv(
{alice: "alice_ml1m.csv", bob: "bob_ml1m.csv"}, keys="ID", drop_keys="ID"
)
label = vdf["Rating"]
data = vdf.drop(columns=["Rating", "Timestamp", "Title", "Zip-code"])
data["UserID"] = data["UserID"].astype("string")
data["MovieID"] = data["MovieID"].astype("string")
sl_model = SLModel(
base_model_dict=base_model_dict,
device_y=bob,
model_fuse=model_fuse,
)
history = sl_model.fit(
data,
label,
epochs=5,
batch_size=128,
random_seed=1234,
dataset_builder=data_builder_dict,
)
INFO:root:Create proxy actor <class 'secretflow.ml.nn.sl.backend.tensorflow.sl_base.PYUSLTFModel'> with party alice.
INFO:root:Create proxy actor <class 'secretflow.ml.nn.sl.backend.tensorflow.sl_base.PYUSLTFModel'> with party bob.
INFO:root:SL Train Params: {'self': <secretflow.ml.nn.sl.sl_model.SLModel object at 0x7f993cf22760>, 'x': VDataFrame(partitions={PYURuntime(alice): Partition(data=<secretflow.device.device.pyu.PYUObject object at 0x7f993cf2e7f0>), PYURuntime(bob): Partition(data=<secretflow.device.device.pyu.PYUObject object at 0x7f993ced0250>)}, aligned=True), 'y': VDataFrame(partitions={PYURuntime(bob): Partition(data=<secretflow.device.device.pyu.PYUObject object at 0x7f993cf3d190>)}, aligned=True), 'batch_size': 128, 'epochs': 5, 'verbose': 1, 'callbacks': None, 'validation_data': None, 'shuffle': False, 'sample_weight': None, 'validation_freq': 1, 'dp_spent_step_freq': None, 'dataset_builder': {PYURuntime(alice): <function create_dataset_builder_alice.<locals>.dataset_builder at 0x7f9a2074f550>, PYURuntime(bob): <function create_dataset_builder_bob.<locals>.dataset_builder at 0x7f9a2074f940>}, 'audit_log_params': {}, 'random_seed': 1234, 'audit_log_dir': None}
0%| | 0/8 [00:00<?, ?it/s]2023-07-25 11:26:40.221001: E tensorflow/compiler/xla/stream_executor/cuda/cuda_driver.cc:267] failed call to cuInit: CUDA_ERROR_NO_DEVICE: no CUDA-capable device is detected
100%|██████████| 8/8 [00:08<00:00, 1.02s/it, epoch: 1/5 - train_loss:0.7806562781333923 train_auc_1:0.4967503547668457 train_precision_1:0.628742516040802 train_recall_1:0.16746412217617035 ]
100%|██████████| 8/8 [00:00<00:00, 15.96it/s, epoch: 2/5 - train_loss:0.6794981956481934 train_auc_1:0.5373517870903015 train_precision_1:0.6171548366546631 train_recall_1:0.9409888386726379 ]
100%|██████████| 8/8 [00:00<00:00, 14.90it/s, epoch: 3/5 - train_loss:0.6782025694847107 train_auc_1:0.5984559655189514 train_precision_1:0.6269999742507935 train_recall_1:1.0 ]
100%|██████████| 8/8 [00:00<00:00, 15.26it/s, epoch: 4/5 - train_loss:0.6483343243598938 train_auc_1:0.6253233551979065 train_precision_1:0.7081005573272705 train_recall_1:0.8086124658584595 ]
100%|██████████| 8/8 [00:00<00:00, 15.86it/s, epoch: 5/5 - train_loss:0.6321477293968201 train_auc_1:0.6638531684875488 train_precision_1:0.6795511245727539 train_recall_1:0.8692185282707214 ]
到此为止,我们已经使用隐语提供的deepfm封装完成了movieLens数据集上的推荐任务训练。