水平联邦:图像分类#
The following codes are demos only. It’s NOT for production due to system security concerns, please DO NOT use it directly in production.
在这个教程中,我们将使用图像分类任务来介绍在secretflow框架下怎样来完成水平联邦学习任务。secretflow框架提供了一套用户友好的api,可以很方便的将您的keras模型或者pytorch模型应用到联邦学习场景,成为联邦学习模型。在接下来的教程中我们将手把手演示,如何将您已有的模型变成secretflow下的联邦模型,完成联邦多方建模任务。
水平联邦学习概念#
这里的联邦学习特指的是水平场景的联邦学习,也就是样本的联合。这种模式适用于各个参与方业务相同,但触达的客户群不同,这种情况可以联合多方的样本来训练一个性能更好或者泛化性能更好的联合模型。比如在医疗场景,每个医院都有自己独特的病人群,各个地区的医院之间几乎是互不重叠,但是他们对于病历的检查记录(如影像,血检等)又是相同类型的。
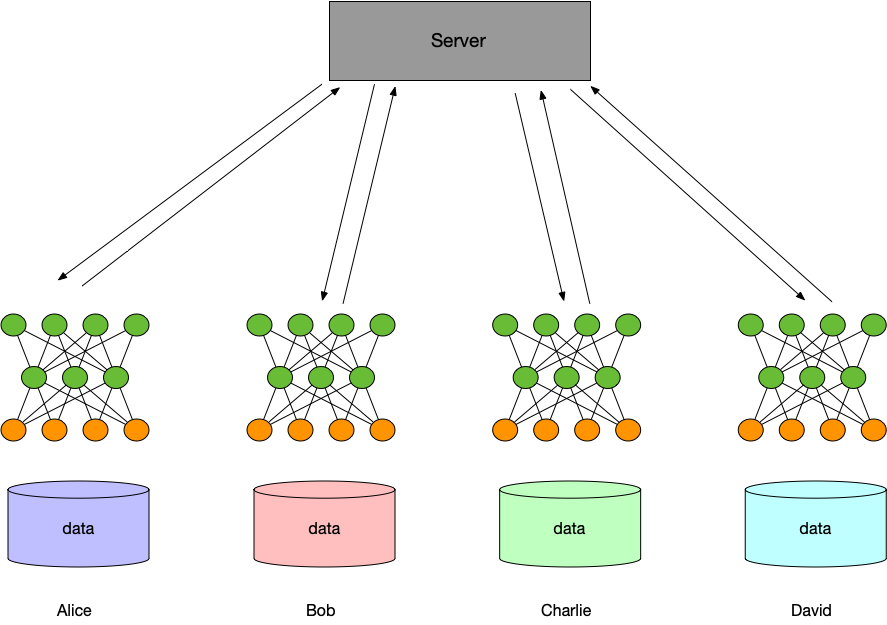
Training process:
Each participant downloads the latest model from the server.
Each participant uses its own local data to train the model, and uploads gradient encryption (or parameter encryption) to the server, which obtains the encryption gradient (encryption parameter) uploaded by all parties for security aggregation at the server, and updates model parameters with the aggregated gradient.
The server returns the updated model to each participant.
Each participant updates their local model, and prepare next training.
使用SecretFlow进行联邦学习#
[1]:
%load_ext autoreload
%autoreload 2
在secretflow环境创造3个实体[Alice,Bob,Charlie],其中 Alice, Bob和Charlie 是三个PYU,Alice和Bob角色是client,Charlie角色是server。
[2]:
import secretflow as sf
# Check the version of your SecretFlow
print('The version of SecretFlow: {}'.format(sf.__version__))
# In case you have a running secretflow runtime already.
sf.shutdown()
sf.init(['alice', 'bob', 'charlie'], address='local')
alice, bob, charlie = sf.PYU('alice'), sf.PYU('bob'), sf.PYU('charlie')
2022-08-18 17:13:51.247907: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcudart.so.11.0'; dlerror: libcudart.so.11.0: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/devtoolset-10/root/usr/lib64:/opt/rh/devtoolset-10/root/usr/lib:/opt/rh/devtoolset-10/root/usr/lib64/dyninst:/opt/rh/devtoolset-10/root/usr/lib/dyninst:/opt/rh/devtoolset-10/root/usr/lib64:/opt/rh/devtoolset-10/root/usr/lib
[3]:
spu = sf.SPU(sf.utils.testing.cluster_def(['alice', 'bob']))
准备训练数据#
Alice 和 Bob 各自拥有一半的数据。
[4]:
from secretflow.data.ndarray import load
from secretflow.utils.simulation.datasets import load_mnist
(x_train, y_train), (x_test, y_test) = load_mnist(
parts=[alice, bob], normalized_x=True, categorical_y=True
)
x_train, y_train, x_test, y_test are both FedNdarray. Let’s take a look at the data obtained from FedNdarray. FedNdarray is a virtual Ndarray built on a multi-party concept to protect data privacy. The underlying data is stored in each participant. The FedNdarray operation is actually performed by each participant on their own local data. The server or other clients do not touch the original data. For demonstration purposes, we will manually download the data to the driver.
This data will be used later in the unilateral model comparison.
[5]:
import numpy as np
from secretflow.utils.simulation.datasets import dataset
mnist = np.load(dataset('mnist'), allow_pickle=True)
image = mnist['x_train']
label = mnist['y_train']
Let’s grab some samples from the data set, and just visually see, what does the data look like for Both Alice and Bob?
[6]:
from matplotlib import pyplot as plt
figure = plt.figure(figsize=(20, 4))
j = 0
for example in image[:40]:
plt.subplot(4, 10, j + 1)
plt.imshow(example, cmap='gray', aspect='equal')
plt.axis('off')
j += 1

[7]:
figure = plt.figure(figsize=(20, 4))
j = 0
for example in image[:40]:
plt.subplot(4, 10, j + 1)
plt.imshow(example, cmap='gray', aspect='equal')
plt.axis('off')
j += 1

从上面两个例子可以看出,Alice和Bob的数据类型和任务都是一致的,但是由于触达的用户群不同,所以样本会有差别。让我们再次拿出之前已经得到的FedNdarray,并对他们做训练接和测试集的拆分来交给后面的训练任务。
定义模型#
[8]:
def create_conv_model(input_shape, num_classes, name='model'):
def create_model():
from tensorflow import keras
from tensorflow.keras import layers
# Create model
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
# Compile model
model.compile(
loss='categorical_crossentropy', optimizer='adam', metrics=["accuracy"]
)
return model
return create_model
训练模型#
导入包
[9]:
from secretflow.security.aggregation import SPUAggregator, SecureAggregator
from secretflow.ml.nn import FLModel
定义模型
[10]:
num_classes = 10
input_shape = (28, 28, 1)
model = create_conv_model(input_shape, num_classes)
定义参与训练的device_list,即之前准备好的各个参与方的PYU。
[11]:
device_list = [alice, bob]
隐语提供了多种聚合方案,SecureAggregator和PPUAggregator可用于安全聚合,更多安全聚合方案可以参考 安全聚合。
[12]:
secure_aggregator = SecureAggregator(charlie, [alice, bob])
spu_aggregator = SPUAggregator(spu)
Define FLModel
[13]:
fed_model = FLModel(
server=charlie,
device_list=device_list,
model=model,
aggregator=secure_aggregator,
strategy="fed_avg_w",
backend="tensorflow",
)
跑起来
[14]:
history = fed_model.fit(
x_train,
y_train,
validation_data=(x_test, y_test),
epochs=10,
sampler_method="batch",
batch_size=128,
aggregate_freq=1,
)
100%|█████████▉| 234/235 [00:04<00:00, 49.26it/s]2022-08-18 17:14:21.735534: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libcuda.so.1'; dlerror: libcuda.so.1: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /opt/rh/devtoolset-10/root/usr/lib64:/opt/rh/devtoolset-10/root/usr/lib:/opt/rh/devtoolset-10/root/usr/lib64/dyninst:/opt/rh/devtoolset-10/root/usr/lib/dyninst:/opt/rh/devtoolset-10/root/usr/lib64:/opt/rh/devtoolset-10/root/usr/lib
2022-08-18 17:14:21.735571: W tensorflow/stream_executor/cuda/cuda_driver.cc:269] failed call to cuInit: UNKNOWN ERROR (303)
100%|██████████| 235/235 [00:18<00:00, 12.61it/s, epoch: 1/10 - loss:0.5259245038032532 accuracy:0.8461666703224182 val_loss:0.14433448016643524 val_accuracy:0.9577999711036682 ]
100%|██████████| 40/40 [00:04<00:00, 8.08it/s, epoch: 2/10 - loss:0.1685342937707901 accuracy:0.9504940509796143 val_loss:0.12423974275588989 val_accuracy:0.964900016784668 ]
100%|██████████| 40/40 [00:02<00:00, 13.97it/s, epoch: 3/10 - loss:0.1499660760164261 accuracy:0.9557806253433228 val_loss:0.11904746294021606 val_accuracy:0.9649999737739563 ]
100%|██████████| 40/40 [00:02<00:00, 14.88it/s, epoch: 4/10 - loss:0.14443494379520416 accuracy:0.9566205739974976 val_loss:0.1067579835653305 val_accuracy:0.9693999886512756 ]
100%|██████████| 40/40 [00:02<00:00, 14.78it/s, epoch: 5/10 - loss:0.1303529143333435 accuracy:0.9610671997070312 val_loss:0.09679792076349258 val_accuracy:0.9718999862670898 ]
100%|██████████| 40/40 [00:02<00:00, 14.61it/s, epoch: 6/10 - loss:0.11564651876688004 accuracy:0.9659584760665894 val_loss:0.09385047107934952 val_accuracy:0.9726999998092651 ]
100%|██████████| 40/40 [00:02<00:00, 14.48it/s, epoch: 7/10 - loss:0.10946863144636154 accuracy:0.9681274890899658 val_loss:0.09159354865550995 val_accuracy:0.972599983215332 ]
100%|██████████| 40/40 [00:02<00:00, 14.81it/s, epoch: 8/10 - loss:0.10932281613349915 accuracy:0.9678359627723694 val_loss:0.08414007723331451 val_accuracy:0.9754999876022339 ]
100%|██████████| 40/40 [00:02<00:00, 14.47it/s, epoch: 9/10 - loss:0.10051391273736954 accuracy:0.9696640372276306 val_loss:0.08173993974924088 val_accuracy:0.9753999710083008 ]
100%|██████████| 40/40 [00:02<00:00, 13.60it/s, epoch: 10/10 - loss:0.10390906035900116 accuracy:0.968478262424469 val_loss:0.07482419162988663 val_accuracy:0.9775000214576721 ]
[15]:
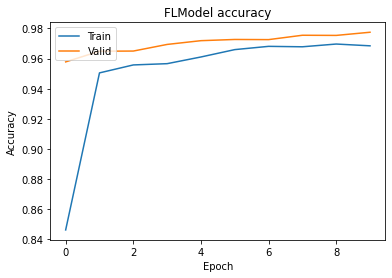
# Draw accuracy values for training & validation
plt.plot(history["global_history"]['accuracy'])
plt.plot(history["global_history"]['val_accuracy'])
plt.title('FLModel accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.legend(['Train', 'Valid'], loc='upper left')
plt.show()
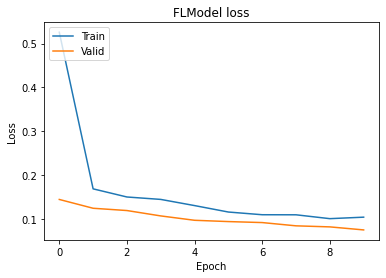
# Draw loss for training & validation
plt.plot(history["global_history"]['loss'])
plt.plot(history["global_history"]['val_loss'])
plt.title('FLModel loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Valid'], loc='upper left')
plt.show()
[16]:
global_metric = fed_model.evaluate(x_test, y_test, batch_size=128)
print(global_metric)
([Mean(name='loss', total=748.24194, count=10000.0), Mean(name='accuracy', total=9775.0, count=10000.0)], {'alice': [Mean(name='loss', total=527.7763, count=5000.0), Mean(name='accuracy', total=4833.0, count=5000.0)], 'bob': [Mean(name='loss', total=220.46567, count=5000.0), Mean(name='accuracy', total=4942.0, count=5000.0)]})
对比单方模型#
模型#
模型结构和上面fl的模型保持一致。
数据#
数据同样使用mnist数据集,单方模型这里我们只是用了切分后的Alice方数据共20000个样本。
[17]:
from tensorflow import keras
from tensorflow.keras import layers
from sklearn.model_selection import train_test_split
def create_model():
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
# Compile model
model.compile(
loss='categorical_crossentropy', optimizer='adam', metrics=["accuracy"]
)
return model
single_model = create_model()
[18]:
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
alice_x = image[:10000]
alice_y = label[:10000]
alice_y = OneHotEncoder(sparse=False).fit_transform(alice_y.reshape(-1, 1))
random_seed = 1234
alice_X_train, alice_X_test, alice_y_train, alice_y_test = train_test_split(
alice_x, alice_y, test_size=0.33, random_state=random_seed
)
[19]:
single_model.fit(
alice_X_train,
alice_y_train,
validation_data=(alice_X_test, alice_y_test),
batch_size=128,
epochs=10,
)
Epoch 1/10
53/53 [==============================] - 1s 16ms/step - loss: 8.1856 - accuracy: 0.5194 - val_loss: 0.5021 - val_accuracy: 0.8461
Epoch 2/10
53/53 [==============================] - 1s 13ms/step - loss: 0.7643 - accuracy: 0.7754 - val_loss: 0.3211 - val_accuracy: 0.9024
Epoch 3/10
53/53 [==============================] - 1s 13ms/step - loss: 0.5189 - accuracy: 0.8452 - val_loss: 0.2557 - val_accuracy: 0.9233
Epoch 4/10
53/53 [==============================] - 1s 14ms/step - loss: 0.3795 - accuracy: 0.8899 - val_loss: 0.1997 - val_accuracy: 0.9388
Epoch 5/10
53/53 [==============================] - 1s 13ms/step - loss: 0.3246 - accuracy: 0.9024 - val_loss: 0.1864 - val_accuracy: 0.9406
Epoch 6/10
53/53 [==============================] - 1s 13ms/step - loss: 0.2747 - accuracy: 0.9182 - val_loss: 0.1696 - val_accuracy: 0.9464
Epoch 7/10
53/53 [==============================] - 1s 12ms/step - loss: 0.2245 - accuracy: 0.9324 - val_loss: 0.1484 - val_accuracy: 0.9545
Epoch 8/10
53/53 [==============================] - 1s 13ms/step - loss: 0.2123 - accuracy: 0.9361 - val_loss: 0.1427 - val_accuracy: 0.9570
Epoch 9/10
53/53 [==============================] - 1s 13ms/step - loss: 0.1884 - accuracy: 0.9425 - val_loss: 0.1290 - val_accuracy: 0.9633
Epoch 10/10
53/53 [==============================] - 1s 13ms/step - loss: 0.1775 - accuracy: 0.9451 - val_loss: 0.1179 - val_accuracy: 0.9627
[19]:
<keras.callbacks.History at 0x7fcd9c53f7c0>
上面两个实验模拟了一个典型的水平联邦场景的训练问题,Alice和Bob拥有类型的图片,每一方只有样本的一部分数据,但是双方的训练目的是一致的如果Alice只用自己的一方数据来训练模型,能够得到一个精确度0.945的模型,但是如果联合Bob的数据之后,可以获得一个精确度接近0.995的模型,而且多方数据联合训练的模型的泛化性能也会更好。
总结#
本篇我们介绍了什么是联邦学习,以及如何在secretflow框架下进行水平联邦学习。
从实验数据可以看出,水平联邦通过扩充样本量,联合多方训练可以提升模型效果。
本文档使用了安全聚合(SecureAggregator)来做演示,secretflow提供了多种聚合方案,您可以在 安全聚合 了解更多信息。
下一步,你可能想尝试不同的数据集,您需要先将数据集进行垂直切分,然后按照本教程的流程进行。